

Thesauri can be defined as “a controlled and structured vocabulary in which concepts are represented by terms, organized so that relationships between concepts are made explicit” (ISO 25964).
However, originally, thesauri (derived from the Greek “θησαυρός”, meaning ‘treasury’ or ‘treasure house’) were not structured vocabularies but words grouped together in relation to their context. The word was first used by Peter Mark Roget in 1852 in the first edition of his work ‘Thesaurus of English Words and Phrases’. Roget organized words not in alphabetical order, but according to their meaning into six classes. It was intended to be used as a reference tool by writers to help them find synonyms or more precise words and phrases for their work.
Officially, thesauri for information retrieval date back to the 1950s when researchers began to apply the word to the vocabulary lists in information systems. In fact, the word was first used in this context in 1957 by Peter Luhn of IBM. In 1959 the first fully operational thesaurus for information retrieval was created by the Dupont Company. However, many of the thesauri developed during this period were lacking mechanisms to distinguish between homonyms (words that have the same spelling but different meaning) and to deal with synonyms (different words with the same meaning) thus making retrieval difficult.
In the 1960s a number of influential thesauri and guidelines for building thesauri were published. One of them is the Thesaurus of Engineering and Scientific Terms (TEST) in 1967, which used the tags BT (Broader Term), NT (Narrower Term) and RT (Related Term) to indicate relations between concepts. It contained an alphabetical sequence of terms, a permuted index, a hierarchical index and a section presenting 22 subject categories.
In the early days most thesauri were compiled manually. Any changes to the relation between the terms had to be done manually. It was an extremely time consuming and prone to human errors process. It was not until the late 1970s that computers began to be used in order to compile thesauri.
In the 1970s and 1980s many commercial online databases used thesauri, either printed or online to enhance the quality of the search.
The use of thesauri in various scientific and technological subjects was boosted by the development, in 1974, of the first international standard for the construction of monolingual thesauri, the ISO 2788. In the last three decades several more construction standards for thesauri have been developed (see relevant paragraph).
The next stage of thesauri development took place with the emergence of the web and the evolution of web-based information retrieval systems and services, and content management systems. This meant that thesauri needed to be adapted to accommodate interoperability of different databases that used a variety of vocabularies, web-dased services and different thesaurus displays namely:
Detailed records for each of the terms showing the preferred term, any non preferred terms, the scope note that clarifies the meaning and usage of the term, the hierarchical, equivalence and associative relations, and possibly, any translations of the term.
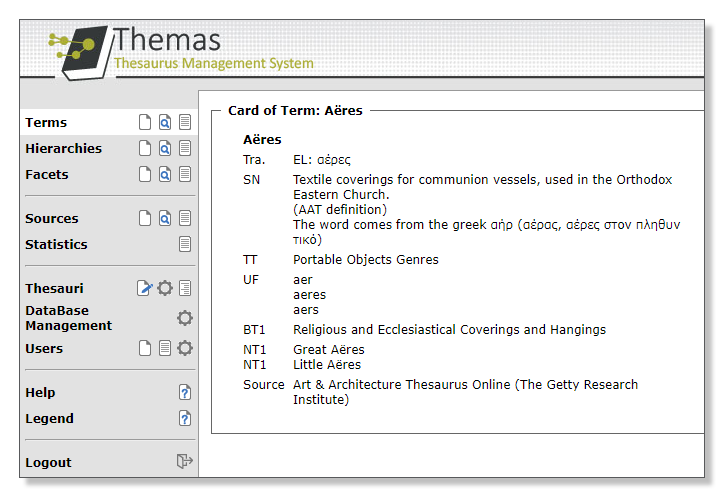
Figure: Example of a record of a thesaurus concept. From the thesaurus of the project "RICONTRANS: Russian Icons Transfer, Visual Culture, Piety and Propaganda: Transfer and Reception of Russian Religious Art in the Balkans and the Eastern Mediterranean (16th – early 20th century)"
Alphabetical displays where all the terms that are included in the thesaurus are arranged in alphabetical order.

Figure: Example of alphabetical display. From the thesaurus of the project "RICONTRANS: Russian Icons Transfer, Visual Culture, Piety and Propaganda: Transfer and Reception of Russian Religious Art in the Balkans and the Eastern Mediterranean (16th – early 20th century)"
Hierarchical displays that show the position on the terms in the hierarchy(s) they belong.
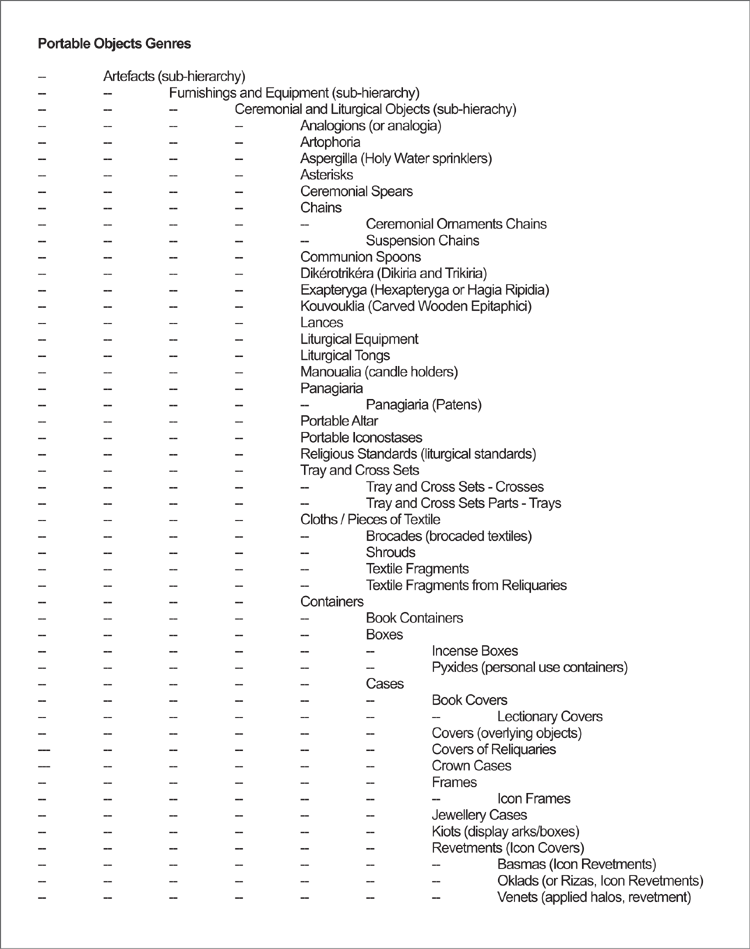
Figure: Example of hierarchical display. From the thesaurus of the project "RICONTRANS: Russian Icons Transfer, Visual Culture, Piety and Propaganda: Transfer and Reception of Russian Religious Art in the Balkans and the Eastern Mediterranean (16th – early 20th century)"
Graphical displays that show terms and their relationships using arrows, tree-like structures and other visualization techniques.
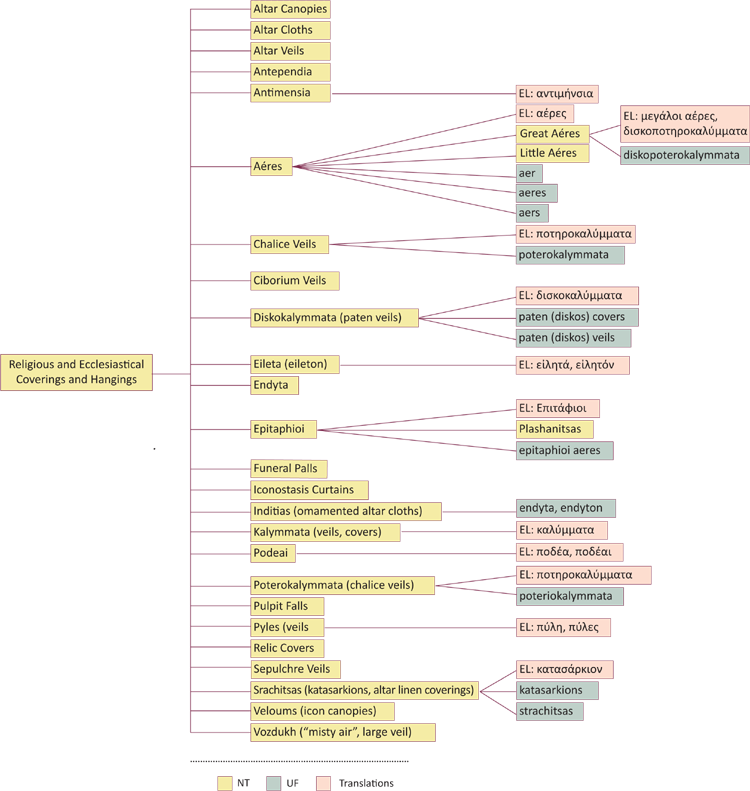
Figure: Example of graphical display. From the thesaurus of the project "RICONTRANS: Russian Icons Transfer, Visual Culture, Piety and Propaganda: Transfer and Reception of Russian Religious Art in the Balkans and the Eastern Mediterranean (16th – early 20th century)"
 which is implemented under the Action “Reinforcement of the Research and Innovation Infrastructure”, funded by the Operational Programme “Competitiveness, Entrepreneurship and Innovation” (NSRF 2014-2020) and co-financed by Greece and the European Union (European Regional Development Fund).")
 which is implemented under the Action “Reinforcement of the Research and Innovation Infrastructure”, funded by the Operational Programme “Competitiveness, Entrepreneurship and Innovation” (NSRF 2014-2020) and co-financed by Greece and the European Union (European Regional Development Fund).")
 which is implemented under the Action “Reinforcement of the Research and Innovation Infrastructure”, funded by the Operational Programme “Competitiveness, Entrepreneurship and Innovation” (NSRF 2014-2020) and co-financed by Greece and the European Union (European Regional Development Fund).")
